
Wybrane Case Study
Opisaliśmy tutaj jeden z naszych projektów, aby zobrazować sposób, w jaki możemy pracować nad Twoim
System zarządzania automatami paczkowymi
Dla klienta z branży produkcyjnej zaprojektowaliśmy, wykonaliśmy oraz utrzymujemy kompleksowy system zarządzania automatami paczkowymi oparty na chmurze Microsoft Azure. W niniejszym case study przedstawiamy wybrane, najistotniejsze aspekty, z którymi mierzyliśmy się projektując ten system.
Kluczowym założeniem projektu była modułowa architektura aplikacji, pozwalająca dostosowywać niewielkim nakładem pracy rozwiązanie do różnych scenariuszy spedycyjnych, które występują wśród sieci handlowych, w których rozwiązanie zostało wdrożone. Charakterystyka rynku obejmuje istnienie wielu sieci handlowych, których sposoby dostarczania zamówień są zróżnicowane. System do obsługi automatów paczkowych musiał umożliwiać przeprowadzenie, u każdego z tych klientów korporacyjnych, procesów przez pracowników i klientów w sposób zintegrowany z dotychczasowymi procesami sieci, działający jako uzupełnienie istniejących ścieżek.
Projekt rozpoczęty został od analizy funkcjonalnej skupiającej się na wszystkich interesariuszach i określającej obszary, w których różne grupy interesariuszy kontaktują się ze sobą. Dodatkowo ocenie podlegał poziom bezpieczeństwa urządzeń dostępowych, z których planowani interesariusze mają korzystać. Na tej podstawie wypracowany został podział systemu na poszczególne jednostki wykonawcze.
Niektóre procesy w związku ze swoją specyfiką wymagają wykonywania w czasie rzeczywistym, jednak złym pomysłem jest z tej przyczyny zaprojektować cały system w dążeniu do synchronicznego wykonywania ogółu operacji. Konieczna jest analiza spodziewanego czasu reakcji poszczególnych aktorów systemu i na tej podstawie pogrupowanie poszczególnych działań w procesach według najdłuższego komfortowego czasu trwania. Pozwala to zaprojektować system w kompromisie pomiędzy bardzo drogą infrastrukturą w której uruchamiane są wyłącznie zasoby obliczeniowe on-demand w momencie wykonywania operacji, a systemem o stałej ilości mocy obliczeniowej, ale działającym zbyt wolno w stosunku do oczekiwań interesariuszy.
Cel został osiągnięty – aktualizacje informacji o zapełnieniu skrytek w automatach dostępne są w ciągu ułamka sekundy (i to rozesłane do każdej aplikacji współpracującej), historie zdarzeń dostępne są po kilkudziesięciu sekundach, natomiast raporty aktualizują się w perspektywie kilku minut. Dodatkowe czynności weryfikujące spójność danych i flagujące ewentualne zdarzenia wymagające ręcznego sprawdzenia przygotowywane są poza godzinami szczytu. Dzięki takiemu kompromisowi czasowemu ilość zasobów obliczeniowych została zminimalizowana, a z tym także ich cena – i to nawet o 66% w stosunku do wariantu, w którym by zaprojektowano system wykonujący wszystkie zadania z równymi horyzontami czasowymi.
Drugi z obszarów wymagający szczególnej uwagi na etapie projektowania Core’a to uprawnienia. Aplikacja ta pełni rolę strażnika spójności informacji w pozostałych podsystemach, w związku z tym konieczne było określenie interfejsów dla pozostałych aplikacji w sposób pozwalający pogodzić odpowiednie role poszczególnych aplikacji z potencjalnym niebezpieczeństwem płynącym z komunikacją z każdą z nich z osobna.
Skąd to niebezpieczeństwo? Generalnie należy zawsze założyć, że aplikacja, której nie mamy pod całkowitą kontrolą (np. jest umieszczona w obcej infrastrukturze klienta, administrowana lub nawet tylko użytkowana przez osoby trzecie) może być potencjalnym źródłem ataków wewnątrz infrastruktury systemu. Dzieje się tak dlatego, że istnieje potencjalna możliwość przejęcia każdego z dostępów interesariuszy przez atakujących i wykorzystania ich do obciążenia innych elementów systemu (tzw. atak lateralny, z ang. lateral movement attack). Dla przykładu, jeśli w systemie istnieją aplikacje A i B, które komunikują się ze sobą, a do aplikacji B dostęp ma np. zewnętrzny serwisant, to gdy celem atakującego jest aplikacja A, może on zamiast szukać drogi dostępu bezpośrednio do niej, zaatakować zewnętrznego serwisanta (np. hakując jego sieć lub urządzenie). Po uzyskaniu od niego dostępów do aplikacji B, atakujący wyznacza procesy, które komunikują się z aplikacją A i stara się ich nadużywać (np. wysyłać ogromne ilości zapytań), aby przeciążyć aplikację A, w nadziei, że ukaże ona w takim scenariuszu jakąś podatność.
Aby zapobiec tym ryzykom Core posiada kilka wyodrębnionych obszarów obejmujących endpointy API udostępniane różnym klasom podsystemów, z których każde jest również wyposażone w szczegółową macierz uprawnień. Dlaczego? Aby instancja innej aplikacji (np. Shepherd, nasz daemon synchronizacji automatów paczkowych w czasie rzeczywistym, o którym piszemy poniżej) miała dostęp wyłącznie do tych elementów bazy danych w swojej klasie, które są do jej działania konieczne. W przypadku próby uzyskania dostępu do innych elementów system podnosi alarm i dokonywana jest weryfikacja, aby możliwie najwcześniej wyizolować potencjalnie zaatakowany fragment systemu. Ponadto rozproszenie dostępu pomiędzy instancjami pozwoliło określić dla nich limity zapytań, co pozwala automatycznie odciąć taki fragment podsystemu w ciągu sekund od wykrycia niepożądanych zachowań.
Dzięki odpowiedniej granulacji systemu tylko niewielka ilość użytkowników końcowych obsługiwana przez daną instancję jest doświadczona przez blokadę, a mechanizm load balancingu pozwala sprawnie (automatycznie) przenieść ich na inną instancję aplikacji, co można powtarzać tak długo, aż wyizoluje się dostęp atakującego (dzieląc przenoszonych użytkowników na więcej instancji).
W sytuacjach, w których konieczna była komunikacja inicjowana również w stronę pozostałych aplikacji, korzystaliśmy z kilku rozwiązań, w zależności od położenia drugiej aplikacji w infrastrukturze. Pomiędzy aplikacjami, nad którymi mamy wyłączną kontrolę, tj. takimi, które są przez nas administrowane w chmurze Microsoft Azure i o których wiemy, że ich architektura została oparta o właściwe założenia dla tej komunikacji, wykorzystujemy Redisa.
Redis jest wysokowydajnym rodzajem bazy danych przechowujących obiekty składające się z kluczy i wartości, a także systemem masowego broadcastowania. Jest popularny w zastosowaniach jako cache ze względu na bardzo krótki czas potrzebny na dostęp do danych (wielokrotnie szybszy niż tradycyjne bazy danych). Z tych zalet korzystamy w komunikacji między aplikacjami.
Dobrą praktyką, w przypadku ponawiania komunikacji z systemami, które nie mają wysokiej dostępności, jest stosowanie kolejnych ponowień z rosnącym odstępem czasu. Tj. pierwsze ponowienie wyślemy od razu, drugie po kilku sekundach, kolejne po kilkudziesięciu, i tak dalej.
Drugi obszar systemu, szczególnie konieczny dla jego funkcjonowania w charakterze sprawnego narzędzia do sterowania fizycznymi urządzeniami i ich diagnostyki, to aplikacja obsługująca komunikację w czasie rzeczywistym, którą nazwaliśmy Shepherd. Zbudowana w środowisku Node.js i obsługująca komunikację socketową przy użyciu socket.io, umożliwia automatom paczkowym podłączanie się i wymianę dużej ilości drobnych komunikatów o zmianie stanu, z których selekcjonowane są informacje istotne dla sprawnego funkcjonowania systemu, które Shepherd podaje dalej.
Założeniem wynikłym z opisanej wyżej analizy bezpieczeństwa było rozdrobnienie Shepherd’a w taki sposób, aby uodpornić się na ewentualne naruszenia bezpieczeństwa płynące ze strony automatu paczkowego. Jest on urządzeniem polowymi i z tego powodu nigdy nie powinien być traktowany jako w pełni bezpieczny, z uwagi na możliwość przeprowadzenia rozległych ataków inkorporujących fizyczną ingerencję w urządzenie. Musieliśmy tak zaprojektować infrastrukturę związaną z obsługą komunikacji z urządzeniami, aby włamanie do jednego z nich nie naraziło całej sieci na przeciążenie. Rozwiązaniem było uruchamianie wielu instancji aplikacji Shepherd, do których przypisane były małe grupy automatów.
Zwrócić należy uwagę na specyficzną sytuację mającą miejsce przy łączeniu się urządzeń z chmurą. W związku z procesem wdrożeniowym urządzenia korzystają z różnego rodzaju dostępu do Internetu, zarówno po kablu (miedź/światłowód), jak i bezprzewodowo (GSM). Niejednokrotnie (zgodnie z naszą rekomendacją) urządzenia mają więcej niż jeden sposób przyłączenia się do sieci, aby zapobiec utracie połączenia na tym polu. Urządzenie po nawiązaniu połączenia z Internetem loguje się do VPN uruchomionego w oparciu o Azure VPN Gateway i od tego momentu może połączyć się z Shepherdem. Z uwagi na specyfikę pracy z Azure VPN Gateway urządzenia dostają zawsze losowe adresy w prywatnej puli. Te okoliczności powodują, że nawiązanie połączenia musi odbywać się z inicjatywy urządzenia i dopiero taka próba połączenia daje nam możliwość sterowania automatem.
Dobrą praktyką jest aby w przypadku urządzeń, które funkcjonują w terenie i same inicjują połączenie z systemem chmurowym, konfigurować w nich więcej niż jeden zestaw poświadczeń i adresów, do których mają się połączyć. Zapobiega to sytuacji, gdy w razie konieczności przeprowadzenia maintenance chmury wymagającego czasowego wyłączenia choćby jednego z elementów kanału dostępu dla urządzeń, urządzenia przestają mieć możliwość połączenia. Gdy urządzenie ma drugi adres, na który może się połączyć w razie niepowodzenia, pozostawiamy sobie przestrzeń na przerwę w działaniu każdego z elementów infrastruktury, również VPNów czy virtualnych przełączników.
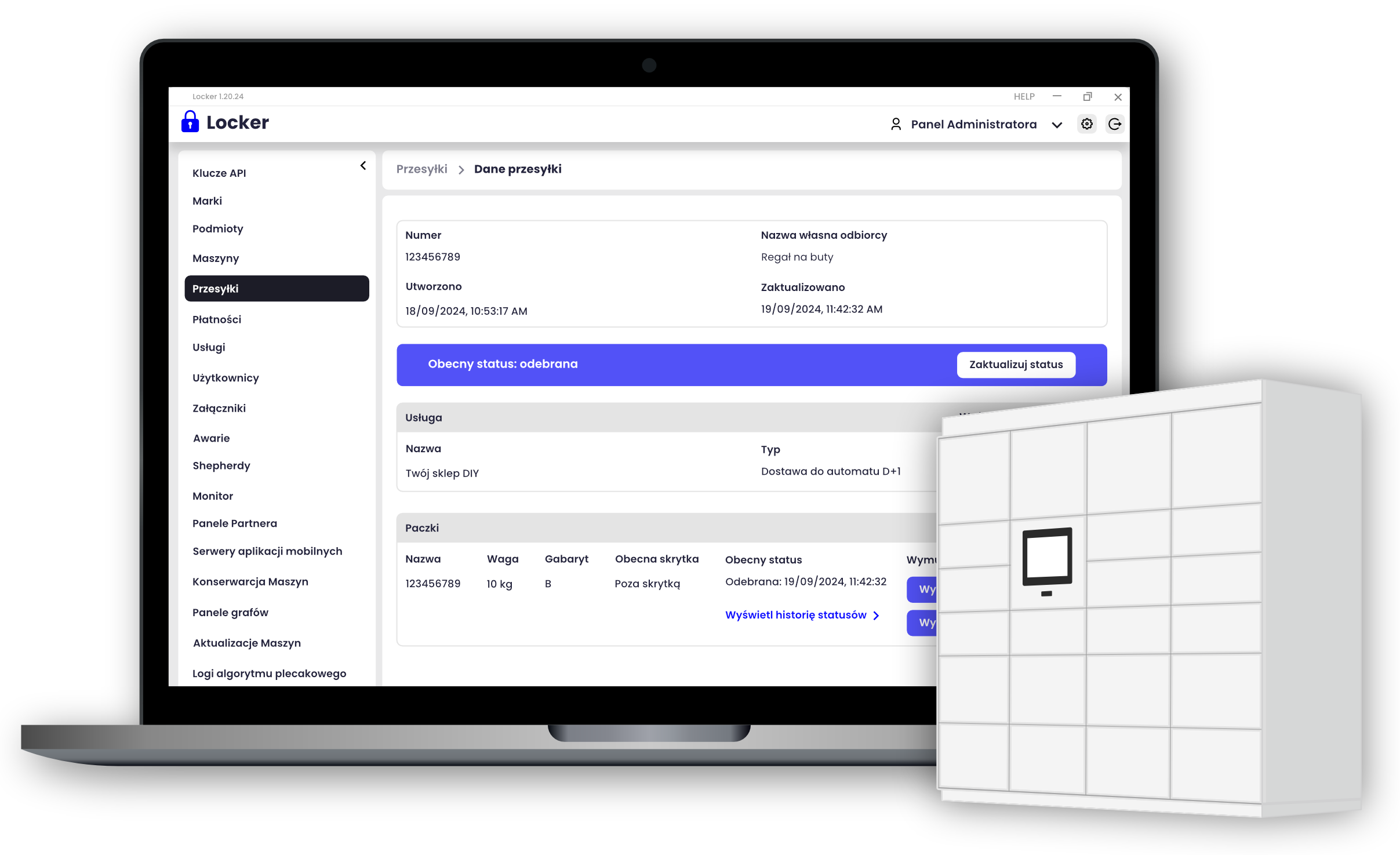
Podłączenie się automatu paczkowego do Shepherda rozpoczyna się od autoryzacji, w której generowany jest czasowy token umożliwiający dalszą komunikację. Preferujemy implementację oAuth 2.0 wszędzie tam, gdzie jest to możliwe. Od momentu prawidłowego pozyskania tokenu rozpoczyna się ciągła komunikacja przez socket.io, która polega na wysyłaniu przez urządzenie wszystkich dostępnych informacji o zdarzeniach. Są to m.in. informacje o stanie zamków, czujników ruchu umieszczonych w skrytkach (dla klientów DIY, gdzie stosowane są skrytki wielkogabarytowe istnieje ryzyko zamknięcia się klienta w środku; monitorujemy to ryzyko i powiadamiamy notyfikacjami na telefonach personel dostępny w pobliżu urządzeń).
Również za pomocą socket.io do urządzenia przekazywane są rozkazy. Najbardziej istotnym z nich jest oczywiście rozkaz otwarcia skrytki (lub jej zamknięcia, w przypadku największych skrytek wyposażonych w pionowe rolety). Aby taki rozkaz dotarł do automatu paczkowego, musi najpierw znaleźć się w Shepherdzie. Służy temu opisana już wcześniej komunikacja przez Redisa, do którego rozkazy docierają z Core’a. Warto zaznaczyć, że w Core każda instancja Shepherda ma oznaczone maszyny, które powinny się z nią skomunikować i na tej podstawie informacje przekazywane przez Redis’y są targetowane do odpowiednich Shepherd’ów.
Istotne jest planowanie procesów mających konkurencyjny dostęp do tego samego zasobu w taki sposób, aby zawsze istniały w nich ścieżki awaryjne, na wypadek konfliktu między operacjami wykonanymi przez dwóch konkurujących użytkowników zasobu. Ta zasada ma zastosowanie zarówno w przypadkach szeroko opisywanych interakcji z bazami danych, ale powyższy przypadek pokazuje, że należy rozważać te same zagadnienia w przypadku zasobów fizycznych.
Laravel Modules to biblioteka, która umożliwia dzielenie aplikacji Laravel’owej na dowolną ilość modułów, w których wyodrębniać można modele, kontrolery, widoki i praktycznie wszystkie inne elementy aplikacji. Projektując aplikcje, które mają być uruchamiane z różnych warunkach i cechować się wymiennością funkcjonalności, projektujemy aplikacje w sposób umożliwiający łatwe odpinanie modułów odpowiedzialnych za poszczególne funkcjonalności. Podobną architekturę ma np. popularny framework sklepowy Magento – warto z tych wzorców czerpać.
W efekcie powstało kilkadziesiąt modułów funkcjonalnych, obejmujących swoim zakresem poszczególne zagadnienia związane z obsługą zamówień, m.in. nadawanie, rezerwacje skrytek, zarządzanie produktami, zarządzanie profilami klientów, generowanie zwrotów, tworzenie raportów, obsługa awaryjnych procesów otwierania i wyjmowania zawartości. Dla każdego tak powstałego modułu jego odpowiednie obszary mające styk z aplikacjami frontendowymi lub innymi systemami (np. aplikacjami preparującymi i propagującymi raporty, które można porównać do wcześniej opisywanego proxy komunikacyjnego dla Core’a) zostały udokumentowane zgodnie ze standardem OpenAPI 3.0.
Istotnym aspektem w sytuacji dużego rozdrobnienia codebase’u aplikacji było przyjęcie odpowiedniej struktury wersjonowania i opisywania dependencies pomiędzy modułami backendowymi oraz między modułami backendowymi a frontendowymi. Przyjęlismy politykę numeracji wersji i utrzymujemy ją w projecie, tak aby nie pozostawiać pola do interpretacji. Do każdej wydanej wersji modułu wprowadzane są numery wersji kompatybilnych modułów zależnych. Ta kompatybilność potwierdzana jest poprzez przeprowadzane testy, o których więcej na końcu niniejszego studium.
Composer to wykorzystywany przez nas menedżer pakietów PHP, który pozwala poradzić sobie z zależnościami nawet w bardzo złożonych projektach. Prawidłowe wersjonowanie składowych modułów aplikacji, a także deklarowanie wzajemnych zależności w aplikacji modułowej pozwala na etapie instalacji na nowej maszynie wyeliminować problemy kompatybilnościowe i doprowadzić do konfiguracji środowiska uruchomieniowego w sposób zaprojektowany (i przetestowany) przez autorów oprogramowania.
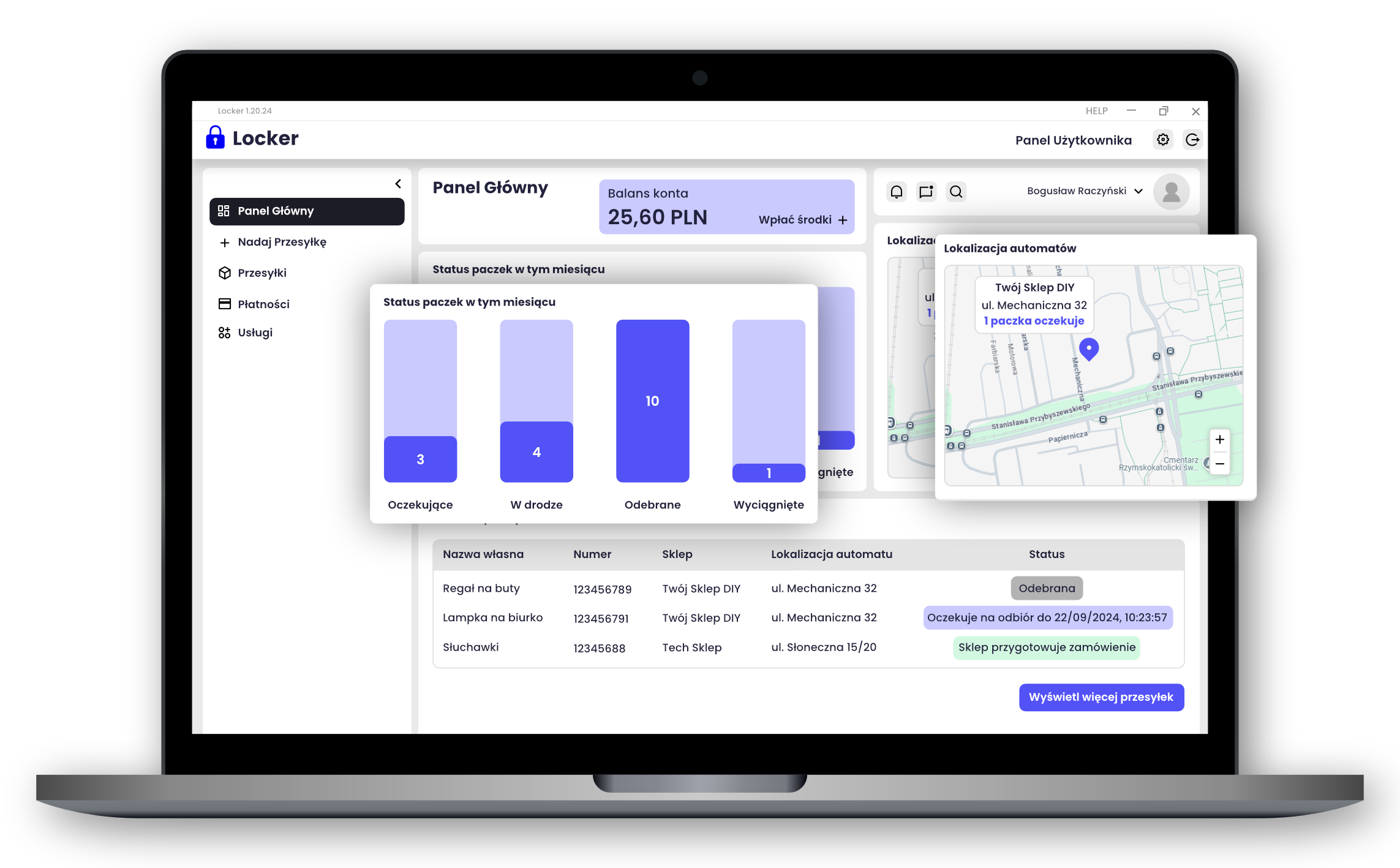
Z perspektywy klienta korporacyjnego, który korzysta z naszego systemu chmurowego, ważnym aspektem jest bezpieczeństwo jego danych, w szczególności informacji o zamówieniach oraz danych osobowych pracowników, którzy je obsługują. W związku z tym do aplikacji Partner przypięliśmy odrębne bazy danych (Partner DBs), które przechowują te informacje wrażliwe z perspektywy biznesowej. Dzięki takiemu fizycznemu oddzieleniu danych wrażliwych od pozostałych zapewniamy najwyższy możliwy poziom bezpieczeństwa. Dane pracowników sieci handlowych nigdy nie trafiają poza daną instancję Partner’a przeznaczoną wyłącznie dla tej sieci, co pozwala minimalizować ryzyka zgodnie z RODO i rygorystycznymi wymaganiami klientów korporacyjnych.
Od strony frontendowej do przygotowania UI dla pracowników sieci wykorzystaliśmy framework Vue, który świetnie sprawdza się do podobnej architektury modułowej, którą wdrożyliśmy w ramach backendu Partner’a. Widoki zostały oparte o podział funkcjonalny i za pomocą konfiguracji mogą być dostosowywane w obrębie szczegółów prezentacji wizualnej.
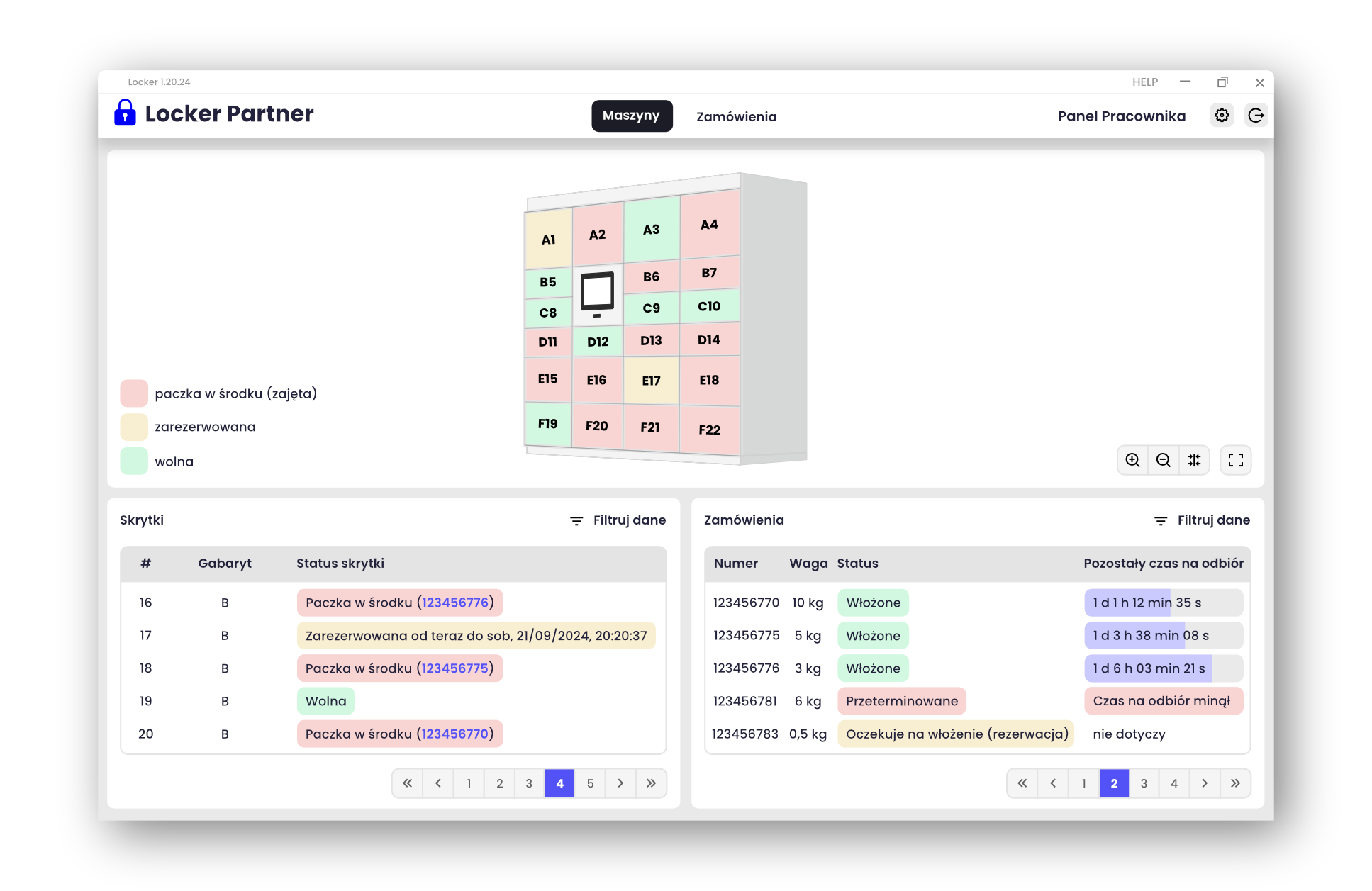
Najważniejszą funkcjonalnością aplikacji Partner jest wkładanie zamówień do automatu paczkowego (wraz z powiązanymi funkcjonalnościami w modułach, np. rezerwacją skrytek). W celu maksymalnego ułatwienia zarządzania urządzeniem przez pracowników, do aplikacji frontentowej został przygotowany model 3D, który pokazuje aktualny stan urządzenia, symulując otwarcia drzwiczek w skrytkach i pokazując za pomocą kolorów zmiany w ich zawartości. Dzięki temu rzut oka wystarczy, aby pracownik oszacował zapełnienie urządzenia i dokonał ewentualnych ręcznych przesunięć (np. przekierować dodatkowe zamówienie z punktu obsługi klienta do automatu paczkowego znajdującego się przed drzwiami sklepu).
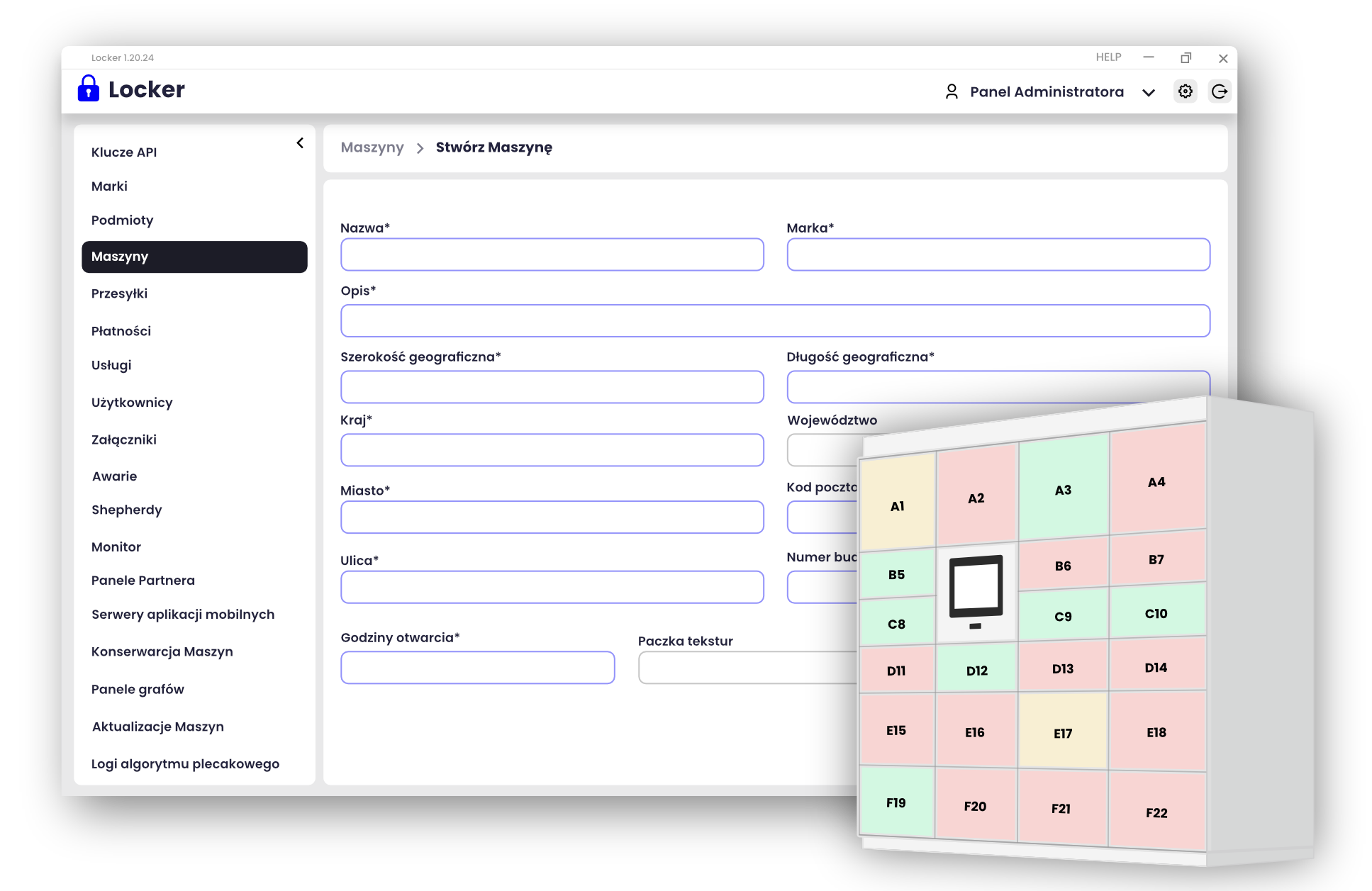
Aby sprostać temu zagadnieniu przygotowaliśmy kreator automatu paczkowego, który za pomocą planszy 2D umożliwia osobie niemającej umiejętności informatycznych skonfigurowanie z klocków nowego automatu paczkowego, którego ściany widoczne są na wizualizacji w trakcie układania skrytek na planszy. Użytkownik Admin Panel’u odpowiedzialny za konfigurację nowego automatu widzi jak powinien wyglądać automat, który właśnie konfiguruje i może łatwo wyłapać ewentualne błędy w wybranych funkcjonalnościach, numeracji, wielkościach czy nazewnictwie skrytek oraz modułów urządzenia. Na podstawie konfiguratora graficznego generowana jest konfiguracja wgrywana do automatu paczkowego, po czym urządzenie może już łączyć się z systemem chmurowym (wymagane jest tylko sprawdzenie kolejności podłączenia skrytek, aby zgadzała się z wygenerowaną konfiguracją).
Wszystkie funkcjonalności Admin Panel’u w trakcie analizy określiliśmy jako możliwe do synchronizacji w dłuższym okresach czasu (poza czasem rzeczywistym, w skali sekund lub minut, zależnie od konkretnego procesu obsługiwanego przez panel). W wyniku tej analizy komunikacja między Admin Panel a Core oparta została o REST API, które umożliwia interakcję z Core’m zachowującą odpowiedni poziom separacji między aplikacją obsługującą działania administratorów, a „sercem” projektu. Dzięki temu zachowany został wysoki poziom zabezpieczenia Core’a przed ewentualnymi próbami ataków.
Obszary administracyjne systemów są szczególnie narażone na umożliwianie ataków powodujących rozległe szkody. Wynika to z zakresu dostępów, jakimi dysponują administratorzy, a przez to ilości informacji, które konto administratora może pobierać z bazy. Proste ataki obciążeniowe polegające na wywoływaniu wielu zapytań zajmujących moce obliczeniowe, będą miały najpoważniejsze skutki właśnie wtedy, gdy do ich przeprowadzenia atakujący uzyska poświadczenia administratorów, mające zwykle dostęp do milionów elementów w bazach.
W związku ze specyfiką opisywaną już wyżej przy okazji aplikacji Partner, dla Partner DBs powstała osobna aplikacja administracyjna (Partner Admin). Wyodrębnienie do niej narzędzi administracyjnych związanych z zarządzaniem i diagnozą stanu zamówień sklepowych pozwoliło zachować separację między danymi szczególnie wrażliwymi, a pozostałą częścią systemu. Struktura projektu w tym obszarze jest podobna do Admin Panel – rozległy system uprawnień dla administratorów pozwala oddzielić osoby obsługujące techniczne czynności od danych osobowych pracowników i klientów, zgodnie z zasadą najmniejszej potrzebnej dawki informacji.
Dobrą praktyką w projektowaniu procesów utrzymaniowych w systemach informatycznych jest konfigurowanie dostępów dla personelu w oparciu o zasadę najmniejszej potrzebnej ilości informacji – projektujemy aplikacje w taki sposób, aby można było przydzielać poszczególnym osobom wyłącznie te elementy, które konieczne są do wykonywania ich pracy.
Aby ułatwić administratorom monitorowanie floty automatów paczkowych, zarówno Admin Panel, jak i Partner Admin, zostały wyposażone w dashboardy, na których graficznie pokazane zostały statystyki wykrytych potencjalnych problemów i stanów urządzeń, w podziale na grupy i lokalizacje, pozwalające wyznaczyć takie urządzenia, dla których należy rozważyć prewencyjne interwencje serwisowe. Takie podejście do monitorowania pozwala rozwiązywać większość problemów występujących z automatami paczkowymi zanim problemy te staną się bardzo dotkliwe dla użytkowników końcowych.
Apache JMeter to narzędzie do projektowania i uruchamiania testów, wychodzące poza pojedynczy protokół. Umożliwia opieranie różnych części projektowanego testu automatycznego na komunikacji z różnymi aplikacjami przy użyciu wielu protokołów. W naszym przypadku konieczne było sprzężenie w testach komunikacji w oparciu o REST API oraz Socket.io, co jest możliwe w JMeterze przy użyciu samplerów do WebSocketów (na których Socket.io jest oparte).
Co zdecydowało o sukcesie projektu?
1. Modułowa budowa
Dzięki podejściu modułowemu możliwe było implementowanie różnych przepływów procesu spedycyjnego dla różnych sieci, przy zachowaniu tych samych elementów aplikacji
2. Oparcie na sprawdzonej chmurze
Wybór Microsoft Azure jako chmury, na której uruchomimy zasoby projektu był kluczowym elementem strategii umożliwiającej szybkie i niezawodne skalowanie wdrożeń. Nowe funkcjonalności, niezależnie jak bardzo wymagające obliczeniowo mogły być wdrażane produkcyjnie niemal bez downtime’u (np. własny model algorytmu plecakowego rozwiązujący problem upakowania towaru w 3D, z uwzględnieniem wagi i specyfiki materiałów opakowaniowych).
3. Separacja aplikacji między klientami
Wyobraź sobie, że obsługujesz jedną usługą dwóch klientów, którzy są dla siebie bezpośrednimi konkurentami – takie sytuacje są częstym problemem handlu, szczególnie branży DIY, gdzie graczy jest niewielu. Zaprojektowaliśmy system w sposób gwarantujący pełną izolację zasobów bazodanowych, tak aby nawet w przypadku błędów lub ataku hakerskiego dane każdego z klientów były bezpieczne i niemożliwe było ich wymieszanie. Osiągnięto to poprzez podzielenie systemu na wiele aplikacji, z których kluczowe komunikują się ze sobą z zachowaniem zasady ograniczonego zaufania i szczegółowego ograniczania uprawnień.
4. Dobre planowanie utrzymania
Kluczowe dla projektu było również dobre zaprojektowanie procesów utrzymania. Sytuacje, w których klienci nie są w stanie odebrać zamówień wielkogabarytowych, takich jak kanapa czy paleta cementu, wymagają traktowania każdej przesyłki z wysoką dbałością. Sprawny system zgłaszania problemów w każdej z aplikacji, z których korzystali klienci i pracownicy sieci handlowych i półautomatyczna weryfikacja zgłoszeń pozwoliły skrócić czas obsługi problemu, tak aby klient nie odszedł od automatu z pustymi rękoma.